GraphQL API
GraphQL API では、Strapi の GraphQL プラグイン 経由で コンテンツタイプ をクエリ・ミューテーションできます。結果は フィルター、ソート、ページネーション で絞り込み・並べ替え・分割取得できます。
GraphQL API を使うには、GraphQL プラグインをインストールします。
- Yarn
- NPM
yarn add @strapi/plugin-graphql
npm install @strapi/plugin-graphql
インストール後、GraphQL Playground は /graphql で開けます。クエリやミューテーションを対話的に組み立て、コンテンツタイプに合わせたスキーマドキュメントを参照できます。
GraphQL プラグインは、すべてのクエリとミューテーションを処理するエンドポイントを 1 つだけ公開します。既定は /graphql で、プラグイン設定ファイル で定義されます。
export default {
shadowCRUD: true,
endpoint: '/graphql', // <— single GraphQL endpoint
subscriptions: false,
maxLimit: -1,
apolloServer: {},
v4CompatibilityMode: process.env.STRAPI_GRAPHQL_V4_COMPATIBILITY_MODE ?? false,
};
GraphQL API ではメディアファイルのアップロードに対応していません。ファイルのアップロードは REST API の POST /upload を使い、返却情報をコンテンツから参照してください。アップロード済みメディアの更新・削除は、メディアの id を使った updateUploadFile と deleteUploadFile ミューテーションで行えます(メディアファイルのミューテーション を参照)。
documentId のみGraphQL API でドキュメントとして公開される識別子は documentId のみです。以前の数値 id はここでは使えません(後方互換のため REST API では引き続き id も返る場合があります。詳しくは 破壊的変更 を参照)。
クエリ
GraphQL のクエリは、データを変更せずに取得するために使います。
プロジェクトにコンテンツタイプを追加すると、スキーマにその単数形・複数形の API ID に対応するクエリが 2 つ自動生成されます。
| コンテンツタイプの表示名 | 単数 API ID | 複数 API ID |
|---|---|---|
| Restaurant | restaurant | restaurants |
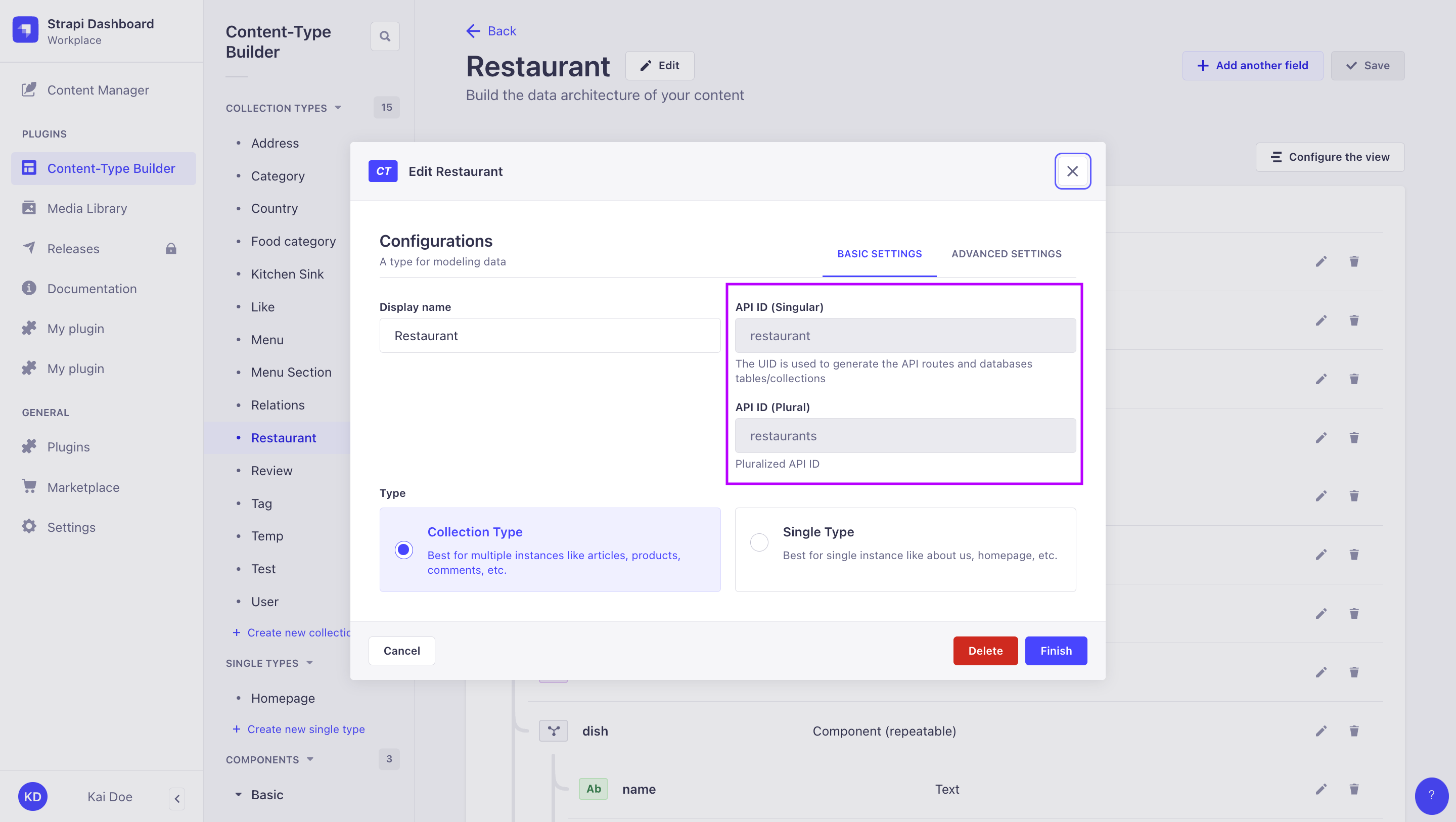
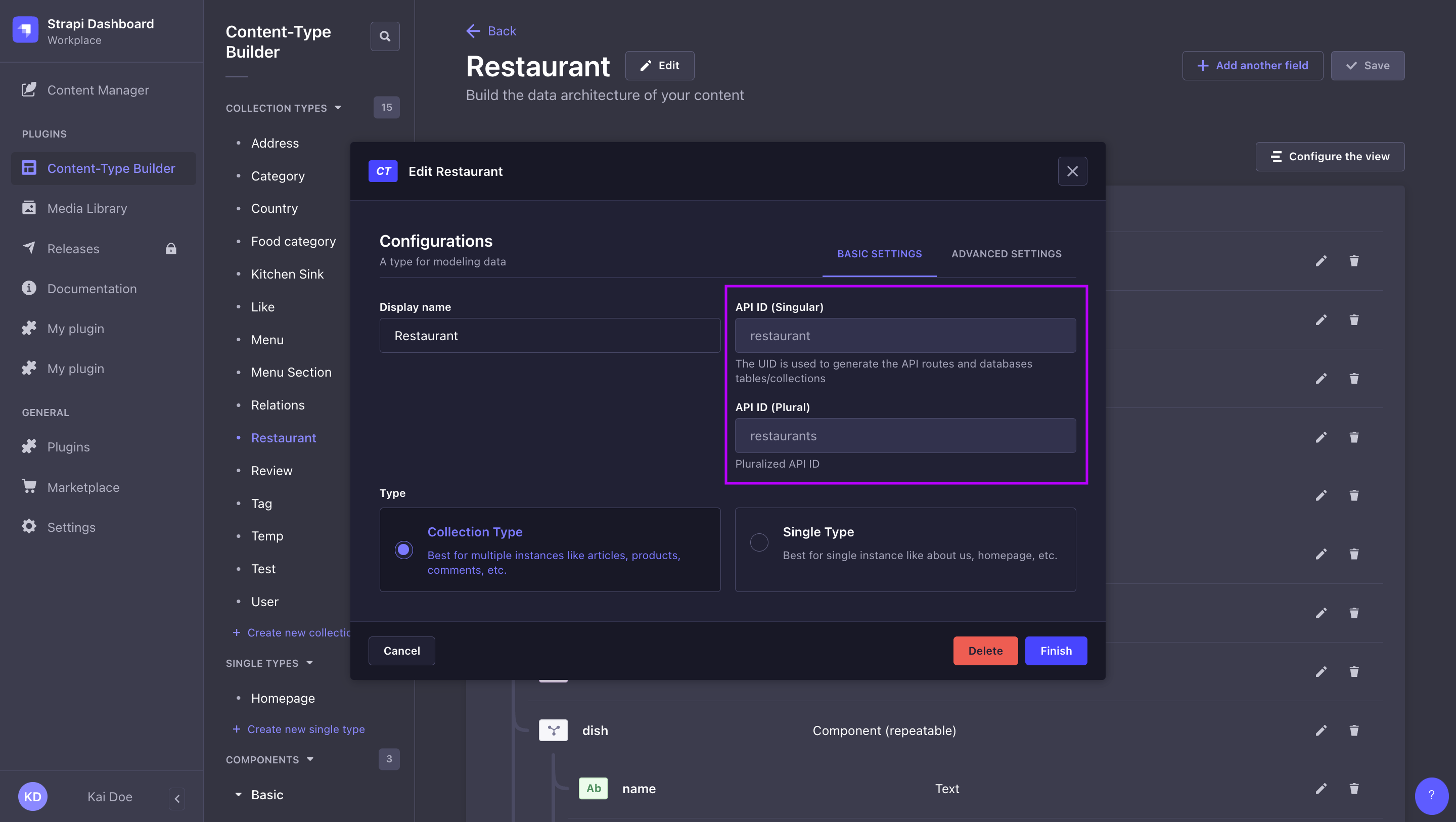
単数 API ID と複数 API ID:
単数・複数の API ID は、Content-Type Builder でコンテンツタイプを作成するときに定義され、管理画面でコンテンツタイプを編集するときにも確認できます(ユーザーガイド を参照)。作成時にカスタム API ID を指定できますが、後から変更はできません。
単一ドキュメントの取得
は documentId で取得できます。
{
restaurant(documentId: "a1b2c3d4e5d6f7g8h9i0jkl") {
name
description
}
}
複数ドキュメントの取得
複数の は、単純なフラットクエリか、Relay 形式のクエリで取得できます。
フラットクエリは、各ドキュメントについて要求したフィールドだけを返します。Relay 形式のクエリは _connection で終わり、nodes 配列と pageInfo を返します。ページネーション用のメタ情報が必要なときは Relay 形式を使います。
- フラットクエリ
- Relay 形式のクエリ
複数件をフラットクエリで取得する例です。
{
restaurants {
documentId
title
}
}
Relay 形式では複数ドキュメントとメタ情報をまとめて取得できます。
{
restaurants_connection {
nodes {
documentId
name
}
pageInfo {
pageSize
page
pageCount
total
}
}
}
リレーションの取得
フラットクエリでも Relay 形式のクエリでも、リレーションのデータを含めて取得できます。
- フラットクエリ
- Relay 形式のクエリ
次の例では、「Restaurant」コンテンツタイプのすべてのドキュメントと、多対多リレーション先の「Category」の一部フィールドを取得します。
{
restaurants {
documentId
name
description
# categories is a many-to-many relation
categories {
documentId
name
}
}
}
Relay 形式で「Restaurant」の全ドキュメントを取得し、各レストランについて「Category」との多対多リレーションの一部フィールドも返す例です。
{
restaurants_connection {
nodes {
documentId
name
description
# categories is a many-to-many relation
categories_connection {
nodes {
documentId
name
}
}
}
pageInfo {
page
pageCount
pageSize
total
}
}
}
現状、pageInfo が有効なのは第 1 階層のドキュメントだけです。将来の Strapi ではリレーションに対する pageInfo が実装される可能性があります。
pageInfo の使い分け:
次の書き方は動作します。
{
restaurants_connection {
nodes {
documentId
name
description
# many-to-many relation
categories_connection {
nodes {
documentId
name
}
}
}
pageInfo {
page
pageCount
pageSize
total
}
}
}
次の書き方はサポートされません。
{
restaurants_connection {
nodes {
documentId
name
description
# many-to-many relation
categories_connection {
nodes {
documentId
name
}
# not supported
pageInfo {
page
pageCount
pageSize
total
}
}
}
pageInfo {
page
pageCount
pageSize
total
}
}
}}
メディアフィールドの取得
メディアフィールドも、他の属性と同様に取得します。
次の例では、「Restaurants」コンテンツタイプの各ドキュメントに付いた cover メディアの url を取得します。
{
restaurants {
images {
documentId
url
}
}
}
複数メディア用フィールドは、フラットクエリまたは Relay 形式で取得できます。
- フラットクエリ
- Relay 形式のクエリ
「Restaurant」コンテンツタイプの複数メディア images から一部属性を取得する例です。
{
restaurants {
images_connection {
nodes {
documentId
url
}
}
}
}
Relay 形式で「Restaurant」の複数メディア images から一部属性を取得する例です。
{
restaurants {
images_connection {
nodes {
documentId
url
}
}
}
}
現状、pageInfo はドキュメントに対してのみ有効です。将来、メディアの _connection に対する pageInfo が実装される可能性があります。
コンポーネントの取得
コンポーネントの内容も、他の属性と同様に取得します。
次の例では、「Restaurants」の各ドキュメントに含まれる closingPeriod コンポーネントについて、label、start_date、end_date を取得します。
{
restaurants {
closingPeriod {
label
start_date
end_date
}
}
}
ダイナミックゾーンの取得
ダイナミックゾーンは GraphQL ではユニオン型になるため、フラグメント(...on)でフィールドを指定します。コンポーネント名は ComponentCategoryComponentname 形式で、`__typename` と組み合わせて使います。
次の例では、ダイナミックゾーン dz に追加できるコンポーネントカテゴリ「Default」の「Closingperiod」について、label を取得します。
{
restaurants {
dz {
__typename
...on ComponentDefaultClosingperiod {
# define which attributes to return for the component
label
}
}
}
}
下書き版・公開版の取得
コンテンツタイプで 下書きと公開 が有効な場合、クエリに status を付けて の下書きまたは公開版を取得できます。
query Query($status: PublicationStatus) {
restaurants(status: DRAFT) {
documentId
name
publishedAt # should return null
}
}
query Query($status: PublicationStatus) {
restaurants(status: PUBLISHED) {
documentId
name
publishedAt
}
}
集計
集計は、すべてのドキュメントを取得せずに件数・合計・グループ集計などを求めるために使います。集計は Relay 形式のコネクションクエリ経由で公開されます。コレクション型ごとに <複数形>_connection クエリの下に aggregate フィールドがあります。
{
restaurants_connection(filters: { categories: { documentId: { eq: "food-trucks" } } }) {
aggregate {
count
}
}
}
集計は親クエリと同じフィルター、ロケール、公開状態、権限の制約を受け�ます。例えばコネクションに locale: "fr" や status: DRAFT を付けると、その条件に合うドキュメントだけが集計対象になり、ユーザーが読み取り可能なコンテンツだけが集計されます。
利用できる集計演算子は次のとおりです。
| 演算子 | 説明 | 対応するフィールド型 |
|---|---|---|
count | クエリに一致するドキュメント数。 | すべてのコンテンツタイプ |
avg | 数値フィールドの算術平均。 | Number, integer, decimal |
sum | 数値フィールドの合計。 | Number, integer, decimal |
min | フィールドごとの最小値。 | Number, integer, decimal, date, datetime |
max | フィールドごとの最大値。 | Number, integer, decimal, date, datetime |
groupBy | 値ごとにバケット化し、各バケットでネストした集計が可能。 | スカラー(string, number, boolean, date, datetime)、リレーション |
avg、sum、min、max では Strapi は null を無視します。リレーションを集計するときも、対象ドキュメントのロケールと権限は尊重されます。
集計はサーバー側で行われるため、大��量データをクライアントに落として処理するより一般的に速いです。ただし groupBy の木が深い、または投影が広いと負荷は高くなります。フィルターで対象を絞り、depthLimit や amountLimit を設定することを検討してください(利用可能なオプション)。You are not allowed to perform this action などは、対象コレクションの Read 権限がない場合に起きがちです。
1 リクエストで複数指標を集計
複数の集計を組み合わせ、1 往復で複数の指標を返せます。
{
restaurants_connection(filters: { takeAway: { eq: true } }) {
aggregate {
avg {
delivery_time
}
min {
price_range
}
max {
price_range
}
}
}
}
グループ化
groupBy でグループごとの指標を求め、各グループ内でさらに集計を連鎖できます。各グループには一意の key と、ドリルダウンや件数カウントに使えるネストした connection があります。
{
restaurants_connection {
aggregate {
groupBy {
categories {
key
connection {
aggregate {
count
}
}
}
}
}
}
}
グループはトップレベルのフィルターを引き継ぎます。特定のグループだけをさらに絞るには、ネストした connection にフィルターを指定します。
ページネーション・ソートとの併用
集計は、クエリのフィルターに一致する結果全体に対して行われ、現在のページの分だけに限りません。ページネーション引数と集計を同じリクエストに含めると、nodes のドキュメントはページ制限に従いますが、aggregate 内の値は pageSize や limit の影響を受けず、条件に合う全体を表します。ソートを付ければ、集計結果と一緒に返るドキュメントの並び順を制御できます。
{
restaurants_connection(
filters: { takeAway: { eq: true } },
pagination: { page: 2, pageSize: 5 },
sort: "name:asc"
) {
nodes {
documentId
name
rating
}
pageInfo {
page
pageSize
total
}
aggregate {
count
avg {
rating
}
}
}
}
ミューテーション
ミューテーションは、データの作成・更新・削除など、変更操作に使います。
コンテンツタイプをプロジェクトに追加すると、 の作成・更新・削除用に GraphQL ミューテーションが 3 つ自動生成され、スキーマに追加されます。
例として「Restaurant」コンテンツタイプでは次のミューテーションが生成されます。
| 用途 | 単数 API ID に基づく名前 |
|---|---|
| 新しい「Restaurant」ドキュメントを作成 | createRestaurant |
| 既存の「Restaurant」を更新 | updateRestaurant |
| 既存の「Restaurant」を削除 | deleteRestaurant |
新規ドキュメントの作成
新規作成では、引数 data の型はコンテンツタイプ専用の入力型になります。
Strapi プロジェクトに「Restaurant」コンテンツタイプがある場合の例です。
| ミューテーション | 引数 | 入力型 |
|---|---|---|
createRestaurant | data | RestaurantInput! |
次の例では「Restaurant」の新規ドキュメントを作成し、name と documentId を返します。
mutation CreateRestaurant($data: RestaurantInput!) {
createRestaurant(data: {
name: "Pizzeria Arrivederci"
}) {
name
documentId
}
}
新規ドキュメントには documentId が自動付与されます。
ミューテーションはリレーション属性にも対応します。例えば新しい「Category」を作成し、複数の「Restaurant」(それぞれの documentId)を紐づけるには次のように書けます。
mutation CreateCategory {
createCategory(data: {
Name: "Italian Food",
restaurants: ["a1b2c3d4e5d6f7g8h9i0jkl", "bf97tfdumkcc8ptahkng4puo"]
}) {
documentId
Name
restaurants {
documentId
name
}
}
}
コンテンツタイプで Internationalization (i18n) が有効なら、特定ロケール向けにドキュメントを作成できます(ローカライズしたドキュメントの作成 を参照)。
既存ドキュメントの更新
既存の を更新するときは、documentId と新しい内容を入れた data を渡します。data の型はコンテンツタイプ専用の入力型です。
「Restaurant」コンテンツタイプがある場合の例です。
| ミューテーション | 引数 | 入��力型 |
|---|---|---|
updateRestaurant | data | RestaurantInput! |
次の例では「Restaurants」の既存ドキュメントの名前を更新します。
mutation UpdateRestaurant($documentId: ID!, $data: RestaurantInput!) {
updateRestaurant(
documentId: "bf97tfdumkcc8ptahkng4puo",
data: { name: "Pizzeria Amore" }
) {
documentId
name
}
}
コンテンツタイプで i18n が有効なら、特定ロケール版を更新できます(i18n の説明 を参照)。
リレーションの更新
リレーション属性は、リレーションの種類に応じて documentId または documentId の配列で更新します。
次の例では、「Restaurant」のドキュメントを更新し、categories フィールド経由で「Category」のドキュメントへのリレーションを追加します。
mutation UpdateRestaurant($documentId: ID!, $data: RestaurantInput!) {
updateRestaurant(
documentId: "slwsiopkelrpxpvpc27953je",
data: { categories: ["kbbvj00fjiqoaj85vmylwi17"] }
) {
documentId
name
categories {
documentId
Name
}
}
}
ドキュメントの削除
を削除するときは documentId を渡します。
mutation DeleteRestaurant {
deleteRestaurant(documentId: "a1b2c3d4e5d6f7g8h9i0jkl") {
documentId
}
}
コンテンツタイプで i18n が有効なら、ドキュメントの特定ロケール版だけを削除できます(i18n の説明 を参照)。
メディアファイルのミューテーション
現状、メディアに対するミューテーションでは Strapi 5 の documentId ではなく、Strapi v4 形式の id を識別子として使います。
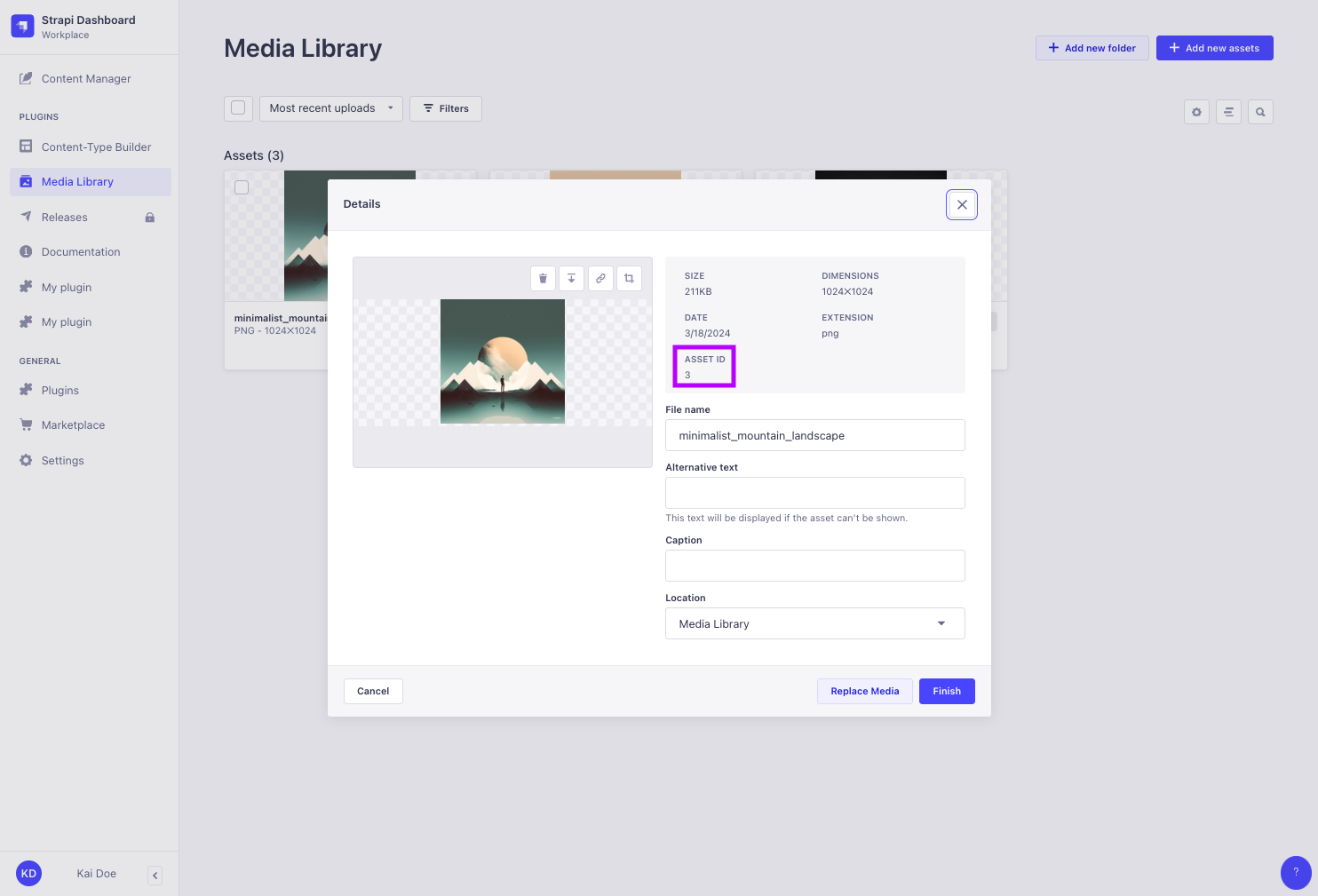
メディアのミューテーションではファイルの id を使います。一方 Strapi 5 の GraphQL クエリでは id は返りません。メディアの id は次の方法で確認できます。
アップロード済みメディアの更新
アップロード済みメディアを更新するときは、メディアの id(documentId ではない)と、新しい内容を入れた info を渡します。info の型はメディア用の入力型です。
例とし�て、プロジェクトに次のミューテーションがある場合。
| ミューテーション | 引数 | 入力型 |
|---|---|---|
updateUploadFile | info | FileInfoInput! |
次の例では id が 3 のメディアの alternativeText を更新します。
mutation Mutation($updateUploadFileId: ID!, $info: FileInfoInput) {
updateUploadFile(
id: 3,
info: {
alternativeText: "New alt text"
}
) {
documentId
url
alternativeText
}
}
アップロード系ミューテーションで forbidden になる場合は、Upload プラグインの権限を確認してください(ユーザーガイド)。
アップロード済みメディアの削除
アップロード済みメディアを削除するときは、メディアの id(documentId ではない)を渡します。
mutation DeleteUploadFile($deleteUploadFileId: ID!) {
deleteUploadFile(id: 4) {
documentId # 返却される documentId
}
}
アップロード系ミューテーションで forbidden になる場合は、Upload プラグインの権限を確認してください(ユーザーガイド)。
フィルター
クエリでは次の形で filters を渡せます。
filters: { field: { operator: value } }
複数条件は組み合わせられ、論理演算子 and、or、not はオブジェクトの配列を受け取れます。複数フィールドの条件を並べた場合は、暗黙の and で結合されます。
and、or、not は互いにネストできます。
利用できる演算子は次のとおりです。
| 演算子 | 説明 |
|---|---|
eq | 等しい |
eqi | 等しい(大文字・小文字を区別しない) |
ne | 等しくない |
nei | 等しくない(大文字・小文字を区別しない) |
lt | より小さい |
lte | 以下 |
gt | より大きい |
gte | 以上 |
in | 配列に含まれる |
notIn | 配列に含まれない |
contains | 含む(大文字・小文字を区別) |
notContains | 含まない(大文字・小文字を区別) |
containsi | 含む(大文字・小文字を区別しない) |
notContainsi | 含まない(大文字・小文字を区別しない) |
null | null である |
notNull | null でない |
between | 範囲内(両端を含む) |
startsWith | 前方一致 |
endsWith | 後方一致 |
and | 論理 AND |
or | 論理 OR |
not | 論理 NOT |
# in - returns restaurants with category either "pizza" or "burger"
{
restaurants(filters: { category: { in: ["pizza", "burger"] } }) {
name
}
}
# notIn - returns restaurants whose category is neither "pizza" nor "burger"
{
restaurants(filters: { category: { notIn: ["pizza", "burger"] } }) {
name
}
}
# null - returns restaurants where description is null
{
restaurants(filters: { description: { null: true } }) {
name
}
}
# notNull - returns restaurants where description is not null
{
restaurants(filters: { description: { notNull: true } }) {
name
}
}
# and - both category must be "pizza" AND averagePrice must be < 20
{
restaurants(filters: {
and: [
{ category: { eq: "pizza" } },
{ averagePrice: { lt: 20 } }
]
}) {
name
}
}
# or - category is "pizza" OR category is "burger"
{
restaurants(filters: {
or: [
{ category: { eq: "pizza" } },
{ category: { eq: "burger" } }
]
}) {
name
}
}
# not - category must NOT be "pizza"
{
restaurants(filters: {
not: { category: { eq: "pizza" } }
}) {
name
}
}
{
restaurants(
filters: {
and: [
{ not: { averagePrice: { gte: 20 } } },
{
or: [
{ name: { eq: "Pizzeria" } },
{ name: { startsWith: "Pizzeria" } }
]
}
]
}
) {
documentId
name
averagePrice
}
}
For examples of how to deep filter with the various APIs, please refer to this blog article.
ソート
クエリでは sort を次の形で渡します。
- 1 キーで並べ替え:
sort: "value" - 複数キー:
sort: ["value1", "value2"]
昇順は :asc(省略可)、降順は :desc を付けます。
{
restaurants(sort: "name") {
documentId
name
}
}
{
restaurants(sort: "averagePrice:desc") {
documentId
name
averagePrice
}
}
{
restaurants(sort: ["name:asc", "averagePrice:desc"]) {
documentId
name
averagePrice
}
}
ページネーション
Relay 形式のクエリでは pagination 引数を渡せます。ページ番号方式かオフセット方式のどちらかで分割取得します。
ページネーションの方式は混在させられません。page と pageSize、または start と limit のいずれか一方だけを使ってください。
ページ番号でページネーション
| パラメータ | 説明 | 既定値 |
|---|---|---|
pagination.page | ページ番号 | 1 |
pagination.pageSize | 1 ページあたりの件数 | 10 |
{
restaurants_connection(pagination: { page: 1, pageSize: 10 }) {
nodes {
documentId
name
}
pageInfo {
page
pageSize
pageCount
total
}
}
}
オフセットでページネーション
| パラメータ | 説明 | 既定値 | 最大 |
|---|---|---|---|
pagination.start | 先頭からのオフセット | 0 | - |
pagination.limit | 取得件数 | 10 | -1 |
{
restaurants_connection(pagination: { start: 10, limit: 19 }) {
nodes {
documentId
name
}
pageInfo {
page
pageSize
pageCount
total
}
}
}
pagination.limit の既定値と最大値は ./config/plugins.js の graphql.config.defaultLimit と graphql.config.maxLimit で設定できます。
locale
Internationalization (i18n) を有効にすると、GraphQL API に次が追加されます。
- スキーマに
localeフィールドが含まれる。 - 次の用途で GraphQL が使える:
特定ロケールのドキュメントをすべて取得
特定ロケールの をすべて取得するには、クエリに locale を渡します。
query {
restaurants(locale: "fr") {
documentId
name
locale
}
}
{
"data": {
"restaurants": [
{
"documentId": "a1b2c3d4e5d6f7g8h9i0jkl",
"name": "Restaurant Biscotte",
"locale": "fr"
},
{
"documentId": "m9n8o7p6q5r4s3t2u1v0wxyz",
"name": "Pizzeria Arrivederci",
"locale": "fr"
},
]
}
}
特定ロケールの 1 件を取得
特定ロケールの を 1 件取得するには、documentId と locale をクエリに渡します。
query Restaurant($documentId: ID!, $locale: I18NLocaleCode) {
restaurant(documentId: "a1b2c3d4e5d6f7g8h9i0jkl", locale: "fr") {
documentId
name
description
locale
}
}
{
"data": {
"restaurant": {
"documentId": "lviw819d5htwvga8s3kovdij",
"name": "Restaurant Biscotte",
"description": "Bienvenue au restaurant Biscotte!",
"locale": "fr"
}
}
}
ローカライズしたドキュメントを新規作成
locale を渡すと、特定ロケール用の を作成できます(ミューテーション全般は GraphQL API のドキュメント を参照)。
mutation CreateRestaurant($data: RestaurantInput!, $locale: I18NLocaleCode) {
createRestaurant(
data: {
name: "Brasserie Bonjour",
description: "Description in French goes here"
},
locale: "fr"
) {
documentId
name
description
locale
}
特定ロケールのドキュメントを更新
ミューテーションに locale を渡すと、指定ロケール版の を更新できます(詳しくは GraphQL API のドキュメント を参��照)。
mutation UpdateRestaurant($documentId: ID!, $data: RestaurantInput!, $locale: I18NLocaleCode) {
updateRestaurant(
documentId: "a1b2c3d4e5d6f7g8h9i0jkl",
data: {
description: "New description in French"
},
locale: "fr"
) {
documentId
name
description
locale
}
ドキュメントのあるロケールを削除
ミューテーションに locale を渡すと、 の特定ローカライズを削除できます。
mutation DeleteRestaurant($documentId: ID!, $locale: I18NLocaleCode) {
deleteRestaurant(documentId: "xzmzdo4k0z73t9i68a7yx2kk", locale: "fr") {
documentId
}
}
高度なユースケース
GraphQL API と Strapi の機能を組み合わせた短いガイドは、次のカードから開けます。